Performance of std::function
In the previous post we saw the implementation of std::function in libstd++ (g++-6.2) in detail and discussed briefly on the libc++ implementation of the same. And now, its time to look at what the performance stats has to say.The platforms and the compilers used for running the performance tests:
- Mac OS Yosemite - clang++ 3.7
- Ubuntu 16.04 VM - g++-6.2
- Ubuntu 16.04 VM - clang++-3.8 (with libc++)
For all tests, the code was compiled with O2 level optimization settings.
I will be trying to benchmark std::function against:
- Virtual function call
- C++11 version of impossibly fast delegate (From StackExchange)
The codes are available at my github repo.
NOTE:
- I would be using 'volatile' in the benchmarking code and stronger data dependency inside tight loops. The use of volatile is to prevent the compiler from optimizing away the code altogether.
- I am including 'iostream' header. :)
- I wasn't really planning to benchmark the 'fast delegate' until I saw THIS reddit post. That left me wandering why std::function was not used.
A note about "Impossibly Fast Delegate"
The implementation simply stores the callable object (pure function pointers and member function pointers) using template hackery and later invoked whenever the delegate call function is invoked, nothing more. This scheme would not work for people who want:
- The stored callable to remain valid outside the lifetime of the class object whose member function needs to be invoked.
- The original implementation did not work for any other types of callbacks. But the c++11 implementation does it in a naive way, i.e to allocate the handler on heap. There is no SBO done.
So, one must be careful while doing comparison of the fast delegate with std::function, just for the reason that std::function can do more things that the "fast delegate" and certainly it would have additional costs if what you want is point #1.
Also, I found on web doing some completely ridiculous benchmarking of boost::function with the fast delegate. The author simply went on creating a new instance of boost::function from a lambda for every iteration, but does not do the same for fast delegate ! I am certainly not planning to do such naive mistakes. I will be keeping the tests as simple as possible to avoid any kind of oversight.
First Round
Here, I am just going to call the callbacks '10000000' number of times and find the total time taken for all 3 on the above mentioned platforms.
Code for Virtual function call:
#include <iostream>
#include <chrono>
constexpr static const int ITER_COUNT = 10000000;
class Base {
public:
virtual volatile int fun_function(volatile int) = 0;
};
class Derived final: public Base {
public:
volatile int fun_function(volatile int i) {
return ++i;
}
};
int main(int argc, char* argv[]) {
Derived d;
Base * b = nullptr;
b = &d;
volatile int v = 0;
auto start = std::chrono::high_resolution_clock::now();
for (int i = 0; i < ITER_COUNT; i++) {
v = b->fun_function(v);
}
auto end = std::chrono::high_resolution_clock::now();
std::cout << std::chrono::duration_cast<std::chrono::microseconds>(end - start).count() << '\n';
}
Code for std::function:
#include <iostream>
#include <chrono>
#include <functional>
constexpr static const int ITER_COUNT = 10000000;
volatile int fun_function(volatile int v)
{
return ++v;
}
int main() {
std::function<volatile int(volatile int)> f(fun_function);
volatile int v = 0;
auto start = std::chrono::high_resolution_clock::now();
for (int i = 0; i < ITER_COUNT; i++) {
v = f(v);
}
auto end = std::chrono::high_resolution_clock::now();
std::cout <<
std::chrono::duration_cast<std::chrono::microseconds>(end - start).count() << '\n';
return 0;
}
Code for "Impossibly fast delegate":
#include <iostream>
#include <chrono>
#include "../impl_fast_delegate.hpp"
constexpr static const int ITER_COUNT = 10000000;
volatile int fun_function(volatile int v)
{
return ++v;
}
int main() {
delegate<volatile int (volatile int)> del(fun_function);
volatile int v = 0;
auto start = std::chrono::high_resolution_clock::now();
for (int i = 0; i < ITER_COUNT; i++) {
v = del(v);
}
auto end = std::chrono::high_resolution_clock::now();
std::cout <<
std::chrono::duration_cast<std::chrono::microseconds>(end - start).count() << '\n';
return 0;
}
And the results are...

My analysis:
- Hmm..in all cases virtual function wins by a massive margin, except for clang on ubuntu.
- The fast delegate is bit faster on both Mac and ubuntu with clang but not on g++-6.2, where std::function wins against the fast delegate. For now, I will consider both std::function and fast delegate equally fast until we do some more micro-benchmarking.
- The results for virtual function on Ubuntu/g++ is very surprising. What makes it do the job so much faster ? Lets have a look at its assembly (with my comments):
movl $10000000, %edx // Setting up the counter value in edx
movq %rax, %rbx
.p2align 4,,10
.p2align 3
.L3:
movl 4(%rsp), %eax // Load the volatile 'v' into eax
addl $1, %eax // Add 1 to the value
subl $1, %edx // Subtract the counter
movl %eax, 4(%rsp) // Save the new value to its actual place
jne .L3 // Loop
Well, it seems that compiler was successfully able to devirtualize the virtual call and further optimize it to make all the computations without calling any function!! Thats brilliant, but more work for me.
Let's change the main function for the virtual function code to:
int main(int argc, char* argv[]) {
Derived d;
Dummy u;
Base * b = nullptr;
if (*argv[1] == '0') {
b = &d;
} else {
b = &u;
}
volatile int v = 0;
auto start = std::chrono::high_resolution_clock::now();
for (int i = 0; i < ITER_COUNT; i++) {
v = b->fun_function(v);
}
auto end = std::chrono::high_resolution_clock::now();
}
I simply added one more derived function and made the decision to point to any one of them via a base class pointer a runtime decision based on command argument.
Lets rerun the tests and see if it changes anything:

Yeah, we now do have a reasonable measurement for virtual function on Ubuntu/g++ combo. But the general analysis is:
Virtual Function Call << std::function <~ Fast Delegate
What makes std::function so much slower than Virtual Function ?
Lets have a look at there corresponding assembly code (on Ubuntu/g++-6.2) (I just hope my comments to the assembly instructions are not way off):
// Assembly for the calling part for Virtual Function
movq %rax, %r12
.p2align 4,,10
.p2align 3
.L5:
movq 0(%rbp), %rax // rax probably points to the VT
movl 12(%rsp), %esi // Move volatile 'v' to esi
movq %rbp, %rdi // Move the 'this' pointer to rdi
call *(%rax)
subl $1, %ebx
movl %eax, 12(%rsp) // The new result stored in eax is stored back.
jne .L5
// Assembly for the calling part for std::function
movq %rax, %rbp
.p2align 4,,10
.p2align 3
.L11:
cmpq $0, 32(%rsp) // Test if callable object is stored
movl 8(%rsp), %eax // Read the volatile 'v' and store it in eax
movl %eax, 12(%rsp) // Store the volatile in eax at a different offset from stack pointer
je .L27 // Jump to exception handling code
leaq 12(%rsp), %rsi // Store the volatile value in rsi
leaq 16(%rsp), %rdi // Store the Any_data union address in rdi
.LEHB0:
call *40(%rsp) // Call the function callable target
subl $1, %ebx
movl %eax, 8(%rsp)
jne .L11
As can be seen, std::function requires more instructions to be executed before making a call to the target callable, 6 instructions again 3 for virtual function.
One thing to not is that, for the std::function case, there is a test against zero for each iteration. This is coming from the below function:
template <typename Res, typename... ArgTypes>
Res
function <Res(ArgTypes...)>::
operator()(ArgTypes... args) const
{
if (M_empty())
throw_bad_function_call();
return M_invoker(M_functor, std::forward<ArgTypes>(args)...);
}
Let's see what happens if we avoid doing this check.


Hmm..std::function seems to beat 'fast delegate' in both #2 and #3 test. Lets look at what is happening on Ubuntu...
Result on Ubuntu using g++-6.2:

Result on Ubuntu using clang++-3.8 using libc++:

Hmm...g++ one certainly did optimize out the #3 and #7 test (or may be not), but I am not interested in that now. What particularly caught my attention is the 11 ns difference in the #2nd test between g++ and clang++.
Other than that, from the above basic test results, I see no reason to go for another delegate implementation rather than using std::function. There may be other interesting test cases to try out, but this is all I have time for as of now :( (This is a way to indirectly ask help from reader to contribute more tests :) ) .
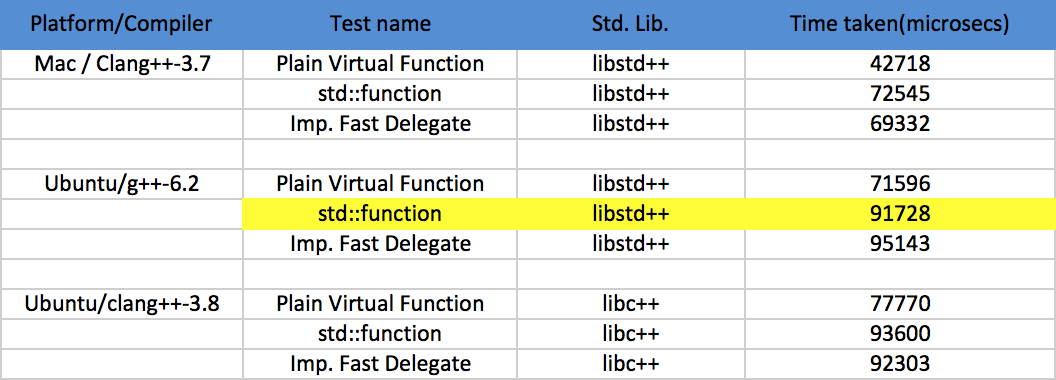
Well, not much difference or no difference at all after removing the check! I am sure I have read it somewhere that removing the check gives increase speedup. Not sure using which compiler and on which platform, but surely it has no effect on Ubuntu using g++-6.2 with O2 optimization.
Let's check the new assembly code just for the hell of it:
.L10:
movl 8(%rsp), %eax
leaq 12(%rsp), %rsi
leaq 16(%rsp), %rdi
movl %eax, 12(%rsp)
call *40(%rsp)
subl $1, %ebx
movl %eax, 8(%rsp)
jne .L10
As can be seen, we no longer have the instructions to make the test against zero and for throwing exceptions. So, I am assuming its the two leaq instructions which is affecting the performance in case of std::function against a virtual function call.
!!!! I wonder if the compiler could have optimized the 2 leaq instructions outside the loop, as they are not changed at all. That would make the instruction cache more hot. !!!!
Second Round
Till now, we saw the benchmarks based upon just using the chrono library and by analyzing the assembly. Let's pimp up the setup. I will be using google benchmark library (on both mac and ubuntu) and perf (only on ubuntu).
The tests are:
- BM_std_function_basic: Same test which we did in first round.
- BM_std_function_heavy: Test which disables SBO i.e with a functor having size big enough which cannot be stored in the internal buffer.
- BM_std_function_poly_cb: Test involving member function callback. Kind of similar to what has been done here.
- BM_virtual_function_basic/48: Same test which we did in first round.
- BM_imp_fast_delegate_basic: Same as #1 but using fast delegate.
- BM_imp_fast_delegate_heavy: Same as #2 but using fast delegate.
- BM_imp_fast_delegate_poly_cb: Same as #3 but using fast delegate.
Result on Mac Os using clang++-3.7:

Hmm..std::function seems to beat 'fast delegate' in both #2 and #3 test. Lets look at what is happening on Ubuntu...
Result on Ubuntu using g++-6.2:

Result on Ubuntu using clang++-3.8 using libc++:

Hmm...g++ one certainly did optimize out the #3 and #7 test (or may be not), but I am not interested in that now. What particularly caught my attention is the 11 ns difference in the #2nd test between g++ and clang++.
Other than that, from the above basic test results, I see no reason to go for another delegate implementation rather than using std::function. There may be other interesting test cases to try out, but this is all I have time for as of now :( (This is a way to indirectly ask help from reader to contribute more tests :) ) .
To go even further beyond....
Can't help but to post this link when the heading is something like this...
Now, let's see why we have a 11 ns difference for the 'heavy' test. Between, I used 'perf' as well to get something out of it, but in that too I ended up annotating the callbacks to show the assembly. So, assembly is all I have to figure out this difference.
Assembly for the clang version:
.LBB2_3:
movq 8(%rbx), %rax
leaq 1(%rax), %rcx
movq %rcx, 8(%rbx)
cmpq 72(%rbx), %rax
jae .LBB2_8
# BB#4:
movl $40, %edi
callq _Znwm // This is where it calls the operator new
movq $_ZTVNSt3__110__function6__funcI10BigFunctorNS_9allocatorIS2_EEFbPKcEEE+16, (%rax)
// Store the Virtual Table in rax
movq %rax, 32(%rsp)
xorps %xmm0, %xmm0
movups %xmm0, 20(%rax)
movl $0, 36(%rax)
movq %r15, 8(%rax)
movl $1735289202, 16(%rax)
#APP
#NO_APP
movq 32(%rsp), %rdi
cmpq %r14, %rdi
je .LBB2_5
# BB#6:
testq %rdi, %rdi
jne .LBB2_7
jmp .LBB2_1
.align 16, 0x90
.LBB2_5:
movq (%rsp), %rax // Prepare for the function call i.e make the arguments ready in register
movq %r14, %rdi
callq *32(%rax) // Call the function, remember rax is now pointing to VT ?
jmp .LBB2_1
.LBB2_2:
movq %rbx, %rdi
callq _ZN9benchmark5State16StartKeepRunningEv
jmp .LBB2_3
Assembly for g++ version:
.L95:
movq 8(%rbx), %rax
cmpq 72(%rbx), %rax
leaq 1(%rax), %rdx
movq %rdx, 8(%rbx)
jnb .L111
movl $32, %edi
movq $0, 32(%rsp)
.LEHB3:
call _Znwm // Invoke the operator new
.LEHE3:
leaq 8(%rsp), %rsi
leaq 16(%rsp), %rdi
// !! This is the start where its trying to zero out
// the buffer inside the functor
movb $0, (%rax)
movb $0, 1(%rax)
movb $0, 2(%rax)
movb $0, 3(%rax)
movb $0, 4(%rax)
movb $0, 5(%rax)
movb $0, 6(%rax)
movb $0, 7(%rax)
movb $0, 8(%rax)
movb $0, 9(%rax)
movb $0, 10(%rax)
movb $0, 11(%rax)
movb $0, 12(%rax)
movb $0, 13(%rax)
movb $0, 14(%rax)
movb $0, 15(%rax)
movb $0, 16(%rax)
movb $0, 17(%rax)
movb $0, 18(%rax)
movb $0, 19(%rax)
movb $0, 20(%rax)
movb $0, 21(%rax)
movb $0, 22(%rax)
movb $0, 23(%rax)
movb $0, 24(%rax)
movb $0, 25(%rax)
movb $0, 26(%rax)
movb $0, 27(%rax)
movb $0, 28(%rax)
movb $0, 29(%rax)
movb $0, 30(%rax)
movb $0, 31(%rax)
movq %rax, 16(%rsp)
movq $_ZNSt17_Function_handlerIFbPKcE10BigFunctorE9_M_invokeERKSt9_Any_dataOS1_, 40(%rsp)
movq $_ZNSt14_Function_base13_Base_managerI10BigFunctorE10_M_managerERSt9_Any_dataRKS3_St18_Manager_operation, 32(%rsp)
movq $.LC2, 8(%rsp)
call _ZNSt17_Function_handlerIFbPKcE10BigFunctorE9_M_invokeERKSt9_Any_dataOS1_ // Call the target callable
movq 32(%rsp), %rax
testq %rax, %rax
je .L101
leaq 16(%rsp), %rsi
movl $3, %edx
movq %rsi, %rdi
call *%rax // Another call is part of destructor, it calls the _M_manager() function
cmpb $0, (%rbx)
jne .L95
.L110:
movq %rbx, %rdi
.LEHB4:
call _ZN9benchmark5State16StartKeepRunningEv
jmp .L95
Do you see all those per byte memset to 0 ? This is the code doing a reset of the 32 byte buffer inside the functor. I never asked the code to do it anywhere, then why is g++ hell bent on doing it ? Is this a bug in g++? This is might be the reason for the additional 10-11 ns difference. Well, I will try to open a bug report anyways.
Another observable difference from the assembly code is that each iteration executes 2 'call' instructions. One is for the actual target function call and the other is for calling the '_M_manager' function inside the destructor, which based upon the operation passed does the required action. This is a fairly costly operation as well. So, if you are using g++'s libstd++ implementation of std::function, watch out for the above 2 costs.
Sentinel
And that is it! I am done with my intended plan of writing this 3 part blog post about std::function. And I have some take aways:
- Do not shy away from using raw pointer to functions or member function pointers if it can solve your specific problem. It is highly unlikely one would be writing a generic function everywhere. If you are not at all worried about performance, then go ahead use std::function all over the place (responsibly).
- Before considering any such other 'fast' delegates, consider using std::function. If in doubt, measure. If you see anything wrong in my measurements, let me surely know in the comments, I will try to add them in my tests and see the result.
- If you just want to pass a callback to another function, which would then be executed immediately within its call stack, then probably something like below would be more efficient:
template <typename Handler, typename... Args>
auto callback_hndler(Handler&& h, Args&&... args) {
return (std::forward<Handler>(h))(std::forward<Args> args...);
}
callback_hndler([](auto a, auto b) { something(); }, aa, bb );
In such cases making the signature of 'callback_hndler' to take an 'std::function' instead would be a bad decision.
ASIO does something similar in a broad sense for its async operations, but then it goes on to allocate the passed handler on heap since it has to perform the operation on a different call stack. One can use std::function in such scenarios as it lifetime management of the callback for you.
There are few more points/examples that I would have liked to give, but this much is probably already more than enough for knowing about std::function. Guess what ? By this time Goku would have probably already transformed into SSJ3 or is he still screaming ? :)
ASIO does something similar in a broad sense for its async operations, but then it goes on to allocate the passed handler on heap since it has to perform the operation on a different call stack. One can use std::function in such scenarios as it lifetime management of the callback for you.
There are few more points/examples that I would have liked to give, but this much is probably already more than enough for knowing about std::function. Guess what ? By this time Goku would have probably already transformed into SSJ3 or is he still screaming ? :)
No comments:
Post a Comment